|
|
Ở phần 2 theo nhân chủng học (molecular anthropology), ta biết sắc dân Việt Nam (viết
tắt“VN”), nói riêng đàn ông, gồm hơn mười
đám người khác nhau, thuộc về những
Y-DNA haplogroup khác nhau, trong đó cái đámđông nhứt
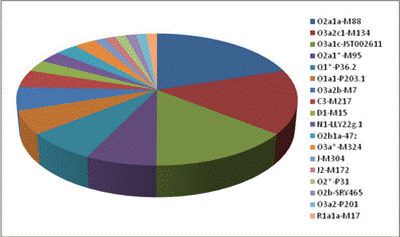
thuộc về haplogroup O2a1a (biểu 1a-b).
Biểu 1a: vẽlại theo Tatiana
Karafet et al [1]
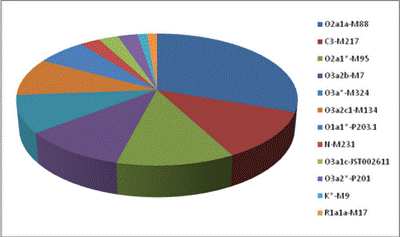
Biểu 1b: vẽ lại theo
Jun-Dong He et al [2] Như vậy, tìm hiểu nguồn gốc người
VN là tìm hiểu nguồn gốc của hơn mười
đám người: họ từ đâu tới, nói thứ
tiếng gì, theo tục lệ gì, đám nào tới trước,
đám nào tới sau,... Nhưng đó chưa phải hết
thảy câu chuyện, mà mới là một nửa. Trong nửa
kia của câu chuyện, đàn bà VN cũng gồm vài
đám người khác nhau thuộc về những
mtDNA haplogroup khác nhau; và ta cũng phải tìm hiểu nguồn
gốc của những đám đàn bà đó, dù
chưa ai dám khoe là hiểu rõ đàn bà. Tóm lại, kể
chuyện nguồn gốc người VN là một việc
khó dàn trời, chớ chẳng phải dễ ăn. Ở phần này, trước hết, ta dợt tiếp
bài học vỡ lòng đã tạm ngưng ở phần
2. Deoxyribonucleic acid (viết tắt “DNA”), nói sơ sài, là một
dãy những nucleotide nối tiếp nhau, mỗi nucleotide
mang một cái base hoặc là adenine (viết tắt “A”), hoặc
là guanine (viết tắt “G”), hoặc là cytosine (viết tắt
“C”), hoặc là thymine (viết tắt“T”). Thứ tự của
những nuceotide trên dãy, theo một hướng nào đó
làm chuẩn, chính là cái information hướng dẫn cách gầy
dựng và giữ gìn một cơ thể. DNA thường
gồm hai dãy giống như hai cạnh của một cái
thang mà mỗi bậc thang là một cặp base (base pair, viết
tắt “bp”) gắn với nhau: A gắn với T, C gắn
với G; thí dụ dãy này có chuỗi AATTGACAT thì dãy kia sẽ
có chuỗi ATGTCAATT theo hướng ngược lại
(hình 1).
Hình 1 DNA được “gói” thành những chromosome (nhiễm
sắc thể) trong mỗi nhân tế bào; con người
có 23 cặp chromosome với hơn 3 tỉ bp, riêng cái Y
chromosome trong cặp số23 mà ông Trời dành riêng cho
đàn ông thì có hơn 57 triệu bp. (Còn một thứ DNA
nữa trong mỗi cái mitochondrion trong từng tế bào, viết
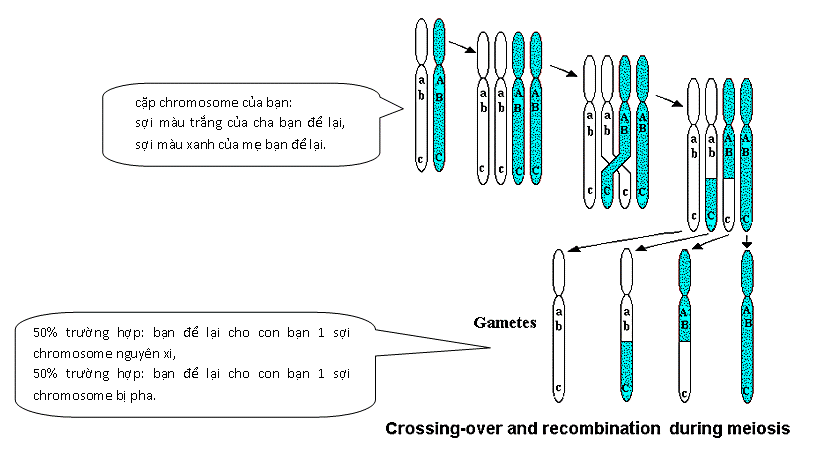
tắt “mt-DNA”, thì không nói ở đây.) Thí dụ vợ chồng bạn đẻ một
đứa con trai, bạn để lại cho nó một sợi
chromosome và vợ bạn để lại cho nó một sợi
chromosome. Riêng cái sợi chromosome của bạn để
lại cho nó chính là sợi của cha bạn hoặc là sợi
của mẹ bạn để lại, nhưng không phải
100% trường hợp đều là nguyên xi, mà trong 25% trường
hợp thì sợi của cha bạn sẽ bị pha một
mẩu của mẹ bạn và trong 25% trường hợp
thì sợi của mẹ bạn sẽ bị pha một mẩu
của cha bạn (hình 2). Tới khi con trai bạn để lại cho cháu bạn
cái sợi-đã-bị-pha nói trên thì sợi đó lại bị
pha thêm một mẩu của vợ bạn trong 25% trường
hợp. Như vậy, DNA của bạn khi truyền lại
con bạn thì đã mất một chút, từ con bạn
truyền lại cháu bạn thì mất thêm một chút nữa,
cho tới đứa cháu đời thứ một
trăm của bạn (hơn 2 ngàn năm sau) thì có thể
nó không còn mang một miếng DNA nào của bạn truyền
lại nữa, dù vậy nó vẫn là “ đích tôn”của bạn.
Hình 2 Riêng cái sợi Y chromosome chung cặp số 23 với sợi
X chromosome thì khác hẳn: sợi Y chỉcó thể pha với
sợi X ở hai đầu, còn khúc giữa chiếm 95% bề
dài sợi Y, gọi là male specific region, thì không bao giờ pha mà cứ
thế truyền từ đời này sang đời khác: … ® ông cố nội ® ông nội ® cha
® con trai ® cháu trai ® … và tới đời thằng cháu đời thứ một
trăm của bạn, nó vẫn giữ nguyên xi Y-DNA của
bạn. Song le, thỉnh thoảng, vào một đời nào
đó, lại xảy ra một cái mutation (khác biệt
đột ngột) cho DNA trên bất kỳ chromosome nào,
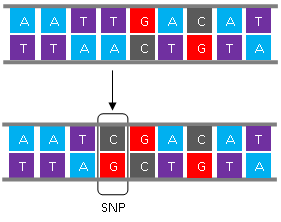
theo vài cách chẳng hạn như sau:
Hình 3
Mỗi cái mutation nói trên ít khi nào xảy ra 2 lần ở
2 người khác nhau, nên được gọi là “unique
event polymorphism”. Mutation nếu xảy ra trong một vùng đặc biệt
của DNA gọi là “gene” thì nó có thể gây hại cho
người và như vậy không truyền được
qua nhiều đời; nhưng nếu nó xảy ra bên
ngoài gene thì nó chẳng làm chết thằng tây nào và cứ
thế truyền mãi tới ngày nay. Nếu bạn mang một cái mutation trên một chromosome
nào đó không phải Y chromosome, thì như đã nói trên, tới
đứa cháu đời thứ một trăm của bạn,
có lẽ cái mutation đó sẽ mất tiêu. Nhưng nếu bạn mang một cái mutation trên Y
chromosome, thì như đã nói trên, tới đứa cháu trai
đời thứ một trăm của bạn, cái
mutation đó vẫn còn nguyên; và nếu lúc đó đàn cháu
mang cái mutation đó đã đông người (ít nhứt
1% dân số đực rựa trên trái đất) thì cái
mutation đó trở thành một “dấu hiệu” (marker) chắc
chắn để phân biệt nhóm đực rựa nào
mang nó với một nhóm đực rựa khác không mang nó,
mỗi nhóm gọi là một Y-DNA haplogroup (viết tắt
“hg”) có chung ông tổ là người đầu tiên mang cái
marker đó. Xem thêm hình 4.
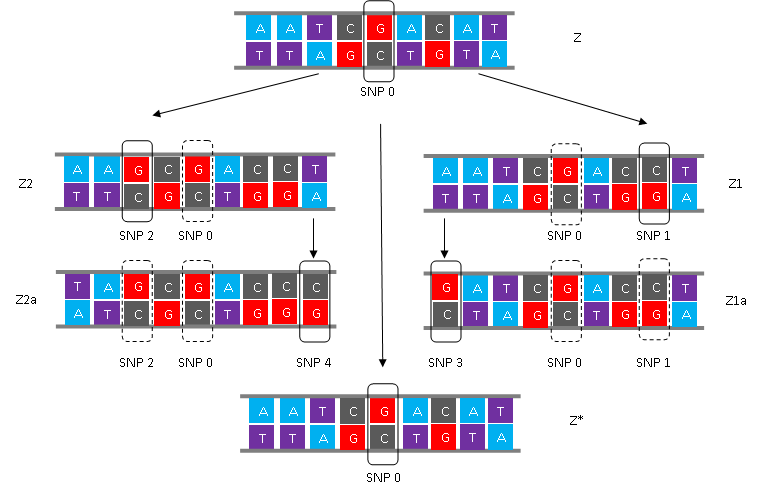
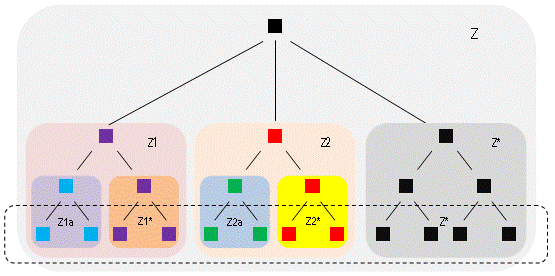
Hình 4 Thí dụ ta bắt đầu từ hg Z với marker
SNP 0, theo dòng thời gian sẽ có:
Nếu dưới Z1a và Z2a không có thêm nhánh mới nào
khác, 5 đám đó đều có đực rựa nối
dõi, và tất cả vẫn sống chung tới bây giờ
thành một nhóm, thì nhóm đó bao gồm 5đám đực
rựa thuộc về 5 hg: Z1a, Z1*, Z2a, Z2* và Z*, có chung ông tổ
là người đầu tiên mang cái marker SNP 0 (hình 5).
Hình 5 Ta có: Z = Z1 + Z2 + Z* Z1 = Z1a + Z1* Z2 = Z2a + Z2* Z(xZ1) = Z2 + Z* = mọi nhánh của Z mà
không phải Z1 Thường thì 5 đám đó không ở lại cùng
nơi mà chia nhau đi bốn phương trời rồi
sống chung với những đám khác nữa, cuối
cùng thành ra những sắc dân khác nhau. Bởi vậy, sắc dân nào bây giờ cũng là một
mớ hổ lốn những đám đực rựa thuộc
về những hg khác nhau, dù bề ngoài có vẻ như là
một đám, nói cùng thứ tiếng, theo cùng văn hóa.
Thí dụ như sắc dân VN mà ta đã nêu (biểu 1a-b). Một
thí dụ nữa, mấy anh chàng ở hình 6 dưới
đây đều là người của sắc dân Hán,
nhưng có thể thuộc về những hg khác nhau.
Hình 6 Cho nên, nói sắc dân này là hoặc
không phải là sắc dân kia, thì không có nghĩa gì hết. Hiểu ra điều đó, trên con
đường đi tìm nguồn gốc, ta sẽ chẳng
bị lạc vô những chỗ mù sương, tức là
chẳng phải nghĩ đến những điều
không có nghĩa, thí dụ như: 1. người VN (gồm hơn 10 đám) là người
Lạc Việt xưa (chưa biết gồm bao nhiêu
đám) 2. người Lawa (gồm nhiều đám) là người
Lạc Việt xưa (chưa biết gồm bao nhiêu
đám) 3. người
Hẹ (gồm nhiều đám) là người Lạc Việt
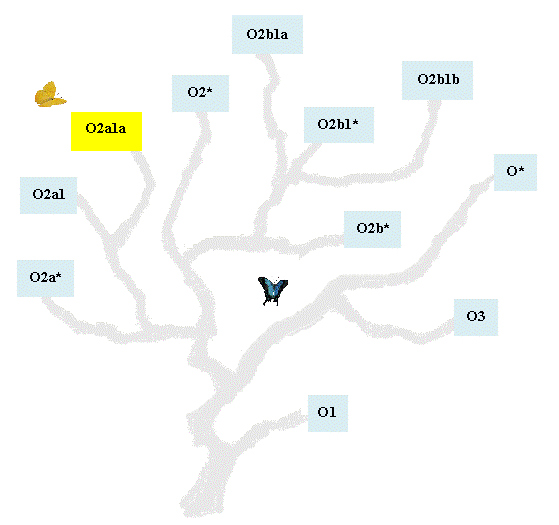
xưa (chưa biết gồm bao nhiêu đám) Hình 7 vẽ một cây hg (Y-DNA haplogroup tree) [3] từ
đó lần lượt mọc ra những hg như là những
cái cành, tượng trưng cho những đám đực
rựa khác nhau trên trái đất ngày nay mà đều là
cháu chắt của một ông tổ sống ở châu Phi
chừng 142,000 năm trước gọi là Y-Adam (hg
màu hồng là ở lại châu Phi, hg màu xanh là đi khỏi
châu Phi).
Hình 7 Ta tạm ngưng bài học vỡ
lòng ở đây, và bắt đầu tìm hiểu những
hg trong sắc dân VN. *** Hình 8 cho thấy O2a1a-M88 (đám đực
rựa đông nhứt của người VN) là nhánh của
O2a1-M95 ở nhánh O2 trên cành O.
Hình 8 Vậy muốn tìm hiểu gốc gác của O2a1a-M88, ta
cần tìm hiểu O2a1-M95 trước, dù gì chừng 10%
đàn ông VN cũng thuộc về O2a1-M95. M95 là một cái SNP mà base C bị đổi thành T: …GATAAGGAAAGACTACCATATTAGTG[C/T]TGGATGGCTTAGCCTTTCCAACCTG... ở vịtrí 20,397,832 trên Y chromosome (hình 9).
Hình 9 (Những cái SNP và indel có ký hiệu “M” là do nhóm nghiên cứu
của Peter Underhill, Ph.D. ở Stanford University, tìm ra.) Mang M95 không phải mặc nhiên là người VN, vì
đàn ông những sắc dân khác cũng có người
mang M95. Mang M95 cũng không làm cho đàn ông có da sậm hơn
hay tóc xoăn hơn, vì M95 không xảy ra trong vùng gene. Nào ta xem O2a1-M95* đang “đầu quân” cho những sắc
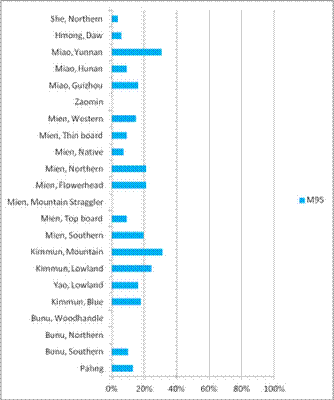
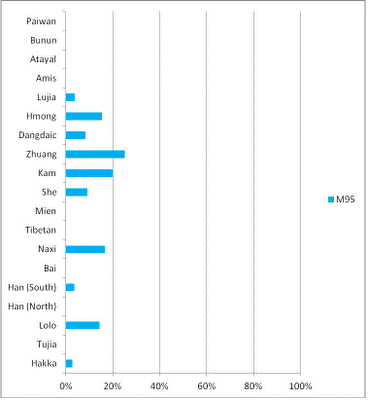
dân nào. Biểu 2. Phần trăm đực rựa thuộc
O2a1-M95* trong 22 nhóm nói những thứ tiếng Hmong-Mien ở
nam TQ, vẽ lại theo Xiaoyun Cai et al [4].
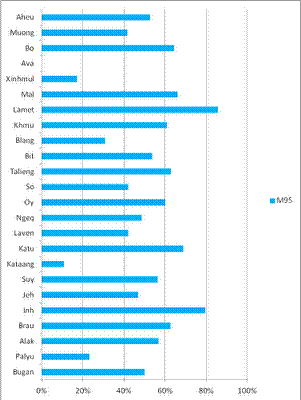
Biểu 3. Phần trăm đực
rựa thuộc O2a1-M95* trong 24 nhóm nói những thứ tiếng
Mon-Khmer ở Đông nam Á, vẽ lại theo Xiaoyun Cai et al
[op. cit.].
Biểu 4: phần trăm đực
rựa thuộc O2a1-M95* trong 15 nhóm Hán và 16 nhóm nói những
thứ tiếng Tibeto-Burman ở TQ, vẽ lại theo Bing
Su et al [5].
Biểu 5: phần trăm đực
rựa thuộc O2a1-M95* trong 31 nhóm ở Vân Nam (TQ), vẽ
lại theo Zhili Yang et al [6].
Biểu 6: phần trăm đực
rựa thuộc O2a1-M95* trong 27 nhóm ở Đông Á, vẽ lại
theo Yali Xue et al [7].
Biểu 7: phần trăm đực
rựa thuộc O2a1-M95* trong 18 nhóm ở TQ, vẽ lại
theo Li Hui et al [8].
Biểu 8: phần trăm đực
rựa thuộc O2a1-M95* trong 9 nhóm đông bắc châu Á và 21
nhóm đông nam châu Á , vẽ lại theo Bing Su et al [9].
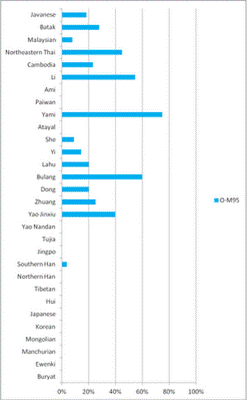
Biểu 9: phần trăm đực
rựa thuộc O2a1-M95* trong 13 nhóm Indonesia và 10 nhóm Oceania, vẽ
lại theo Tatiana Karafet et al [1].
Biểu 10: phần trăm đực
rựa thuộc O2a1-M95* trong 24 nhóm ở đông bắc Ấn
Độ, vẽ lại theo Vikrant Kumar et al [10].
Biểu 11: phần trăm đực
rựa thuộc O2a1-M95* trong 24 nhóm ở đông bắc Ấn
Độ, vẽ lại theo Gyaneshwer Chaubey et al [11].
Biểu 12: phần trăm đực
rựa thuộc O2a1-M95* trong 11 nhóm Đông bắc Á và
Đông nam Á, vẽ lại theo Han Jun-Jin et al [12].
Rất tiếc không có dữ liệu
của những nhóm thiểu số bên VN, trừ hai nhóm
Mường (biểu 3) và Chàm (xem lại bảng 5 phần
2). Nhưng vài nhóm bên VN có lẽ cũng chính là những
nhóm bên Lào mà đã được khảo sát ở biểu
3, thí dụ:
Số liệu từ biểu 2 tới biểu 12, lọc
bớt đôi chỗ khác biệt, cho thấy địa
bàn của đám O2a1-M95* đại khái như sau:
Như vậy, cái gốc của O2a1-M95 có lẽ một
là Lào hai là đông bắc Ấn Độ rồi từ
đó lan ra những nơi khác. Vikrant Kumar et al [op. cit.] cho
rằng cách nay chừng 65 ngàn năm đám O2a1-M95 đã ra
đời trong những nhóm người là tổ tiên của
những nhóm nói tiếng Munda ngày nay ở đông bắc Ấn
Độ,rồi theo những nhóm đó sang Đông nam Á. Given this and the fact that this haplogroup is nearly absent in other
parts of India as well as in Western and Central Asia, one may safely
conclude that O-M95 has originated in Mundari populations roughly around
65,000 YBP (95% C.I. 25,442 – 132,230), as suggested by TMRCA... The
foregoing analysis therefore suggests in-situ origin of O-M95 haplogroup,
most probably in the ancestors of present day Mundari populations, who might
have carried it further to Southeast Asia. (Nói đám O2a1-M95 ra đời cách nay chừng 65 ngàn
năm thì coi bộ hơi quá, vì đám K-M9,
ông tổ của O2a1-M95, cũng mới ra đời từ
40 tới 50 ngàn năm nay thôi.) Ngược lại, Gyaneshwer Chaubey et al [op. cit.] cho rằng
O2a1-M95 ra đời ở Đông nam Á chừng 20 ngàn
năm trước, về sau mới di cư quaẤn
Độ. ...The presence of a significant (approximately one-quarter) southeast
Asian genetic component among Indian Munda speakers is consistent with this
model, implying their recent dispersal from southeast Asia followed by
extensive admixture with local Indian populations. The strongest signal of
southeast Asian genetic ancestry among Indian Austroasiatic speakers is
maintained in their Y chromosomes, with approximately two-thirds falling into
haplogroup O2a. Geographic patterns of genetic diversity of this haplogroup
are consistent with its origin in southeast Asia approximately 20 KYA,
followed by more recent dispersal(s) to India. ...Overall, due to the apparent lack of geographic clustering of Indian
Austroasiatic O2a Y-STR haplotypes in the phylogenetic network, our 15.9± 1.6
KYA age estimate for the Indian subset should not be taken as a genetic
estimate of dispersal time of Austroasiatic groups to India, but rather, this
date estimate can be considered as the upper boundary for any dispersal
event(s) to India that involved the O2a lineage. O2a1-M95* ở Lào và đông bắc Ấn Độ
đều nói những thứ tiếng Austroasiatic (viết
tắt “AA”). Như vậy, “nói tiếng AA” và “thuộc về
hg O2a1-M95*” ắt là hai chuyện có liên quan với nhau chớ
không phải ngẫu nhiên, tức là, đám O2a1-M95* vốn
nói tiếng AA. Bây giờ ta xem mấy nhà ngôn-ngữ-học
cho nguồn gốc của tiếng AA ở đâu (người
VN cũng đang nói một thứtiếng AA). Stanley Starosta [13] cho rằng tiếng AA ra đời bên
trên dòng Dương Tử (hình 10), về sau nhóm nói tiếng
AA bị nhóm nói tiếng Hmong-Mien lấn qua phía tây lên cao
nguyên Vân Nam, sau đó vài đám AA xuôi dòng Mekong và mấy
sông khác đi xuống Lào, vài đám AA đi tiếp qua Miến
Điện và Ấn Độ... Nhữngđám ở lại
trở thành tổ tiên những người nói tiếng
Mon-Khmer, trong đó có mộtđám xuôi dòng Mekong đi xuống
vùng VN-Miên-Lào rồi lại tách ra 5 đám ở lại
Miên và VN... At about the same time the Huang He languages were forming, the language
chain along the Yangzi River, which I will refer to as Proto-Yangzian, took
rice rather than millet as its agricultural staple. It differentiated into
the ancestors of the upriver AA and downriver HM languages. …Subsequent to the HM expansion and possibly as a partial result of it,
the AA language, the other first-order branch of Yangzian, moved west up the
Yangzi River toward the Yunnan Plateau, bringing rice agriculture to this
area. Here it initially prospered and spread southward along the Mekong and
other rivers southeast and south, occupying most of Laos. Other groups
crossed several major watersheds into northern Burma and Assam via the ‘Khasi
Corridor’… ...From Assam, the pre-Mundas followed the Brahmaputra River into the
northeast Indian plain, leaving behind the Khasis in Assam and acquiring many
of the characteristic South Asian phonological and grammatical features from
the previous Dravidian residents. All the remaining AA speakers other than
the Munda are the ancestors of the modern MK languages. A southeastern MK group, Pre-Proto-eastern MK, moved further down the
Mekong River to the Vietnam-Cambodia-Laos border area and split into five
subgroups to occupy Cambodia and Vietnam…
Hình 10 George van Driem [14] cho rằng cái gốc của tiếng
AA là lưu vực sông Brahmaputraở đông bắc Ấn Độ (hình 10, góc dưới bên trái). …Assuming the veracity of the father tongue hypothesis for the spread of
Austroasiatic, the available data could be interpreted as pointing towards
the Brahmaputra basin as the point of origin for this language family. Ilia Peiros [15] thì cho rằng tiếng AA xưa và tiếng
Sino-Tibetan xưa có mượn qua mượn lại, mà ổng
đã đoán cái gốc của Sino-Tibetan là đâu đó gần
Himalaya, nên nếu ổng đoán trúng thì cái gốc của
AA cũng phải kếbên, không xa khúc giữa sông
Dương Tử, có lẽ là miền núi kế đó ở
Tứ Xuyên bây giờ (hình 11). There is a significant number of words that are similar between Proto-AA
and Proto-Sino-Tibetan, which I plan to discuss in a separate publication.
Some of them can also be found in Schuessler’s etymological dictionary of
Chinese [2007] and in [Peiros 1998: 226–27]. Their preliminary analysis
suggests that the protolanguages were in contact, with borrowings travelling
in both directions. Important cultural terms, such as the words for rice,
were, however, excluded from this process. If my suggestion that the
Sino-Tibetan homeland was located somewhere in the Sub-Himalayas [Peiros
1998] is correct, the AA homeland must have been nearby. As may be seen, the discussed evidence altogether supports the proposal
that the AA homeland was located somewhere not far from the mid-Yangtze valley,
probably in the nearby mountains in modern Sichuan, as has been suggested by
Peiros and Shnirelman in 1998.
Hình 11 (Nếu ổng đoán trúng một cái thì có lẽ trúng
hết, trật một cái thì chắc chắn trật hết;
nhưng ta chưa rõ là ổng trúng hay trật.) Ngược lại, Paul Sidwell & Roger Blench [16] cho rằng
cái gốc của tiếng AA là ở khúc giữa sông
Mekong, rồi từ đó lan lên phía bắc và lan xuống
phía nam (hình 12).
Hình 12 Paul Sidwell [17] cũng cho rằng trong 9 thứ tiếng
AA thì hết 7 có lẽ từ cao nguyên Khorat kế sông
Mekong hoặc là miệt gần đó (ô màu đỏ hình
13) mà tách ra, chừng 4000 năm trước. In that case, perhaps 7 out of 9 Austroasiatic branches are located on or
adjacent to the Khorat plateau/Mekong river. Given that rice cultivation did
not arise there before 4300 BP, and Austroasiatic is rich in rice
terminology, we can suggest a dramatic dispersal event around 4000 BP,
broadly consistent with the suggestion of Thomas (1973).
Hình 13 Khorat (Thái
Lan) cách Huế chưa tới 540 km đường chim bay là nơi có địa điểm khảo cổ Ban Chiang
di sản thếgiới, với di tích đồ đồng
từ năm 2000 BC còn xưa hơn cả đồ đồng
Đông Sơn từ năm 1425 ± 100 BC. Bây giờ ta ghé thăm một nhà sinh học làm việc
ở một viện Pasteur. Vì sao vậy? Là vì ta cần biết rằng trong bao tử
của ít nhứt một nửa số người trên
trái đất có con vi khuẩn tên Helicobacter
pylori, nó đã tháp tùng những đám người
di cư ra khỏi châu Phi chừng 60 ngàn năm trước
và đến nay nó đã tách ra thành 7 dòng vi khuẩn khác
nhau ở những vùng khác nhau trong đó có dòng Đông Á mà
người VN đang mang. Ở đây ta không nói chuyện
cái dòng đó lợi hay hại mà là ai đã đem nó từ
đâu tới VN hay là ai đã đem nó từ VN đi chỗ
khác. Sebastien Breurec et al [18] nghiên cứu gene của H. pylori
ở những nhóm người sống những vùng khác
nhau ở Đông nam Á và cho rằng dòng H. pylori
Đông Á đã đi theo tổtiên của đám nói tiếng
Austroasiatic từ TQ xuống VN và Cambodia khi họ di cư
từTQ xuống hai nơi đó chừng 4000 năm
trước. Here, we analyse housekeeping gene sequences of the human stomach
bacterium Helicobacter pylori from various countries in Southeast Asia
and we provide evidence that H. pylori accompanied at least three ancient
human migrations into this area: i) a migration from India introducing
hpEurope bacteria into Thailand, Cambodia and Malaysia; ii) a migration of
the ancestors of Austro-Asiatic speaking people into Vietnam and Cambodia
carrying hspEAsia bacteria; and iii) a migration of the ancestors of the Thai
people from Southern China into Thailand carrying H. pylori of population
hpAsia2. Moreover, the H. pylori sequences reflect iv) the migrations
of Chinese to Thailand and Malaysia within the last 200 years spreading
hspEasia strains, and v) migrations of Indians to Malaysia within the last
200 years distributing both hpAsia2 and hpEurope bacteria. ...Although our data are not conclusive on the source of the
Austro-Asiatic expansion, the tree topology of the subcluster hspEAsia
(Figure 2C) that was supported by AMOVA analyses (Table S3) is consistent
with the hypothesis that ancestors of the Austro-Asiatic people migrated from
southern China into Southeast Asia, introducing hspEAsia bacteria into
Vietnam and Cambodia. This language family might have been spread together
with rice agriculture as part of a Neolithic human diaspora from the Yangzi
and Yellow River Basins in China into Southeast Asia. The settlement of
Southeast Asia has been dated from about 2000 BC... Xem đường màu vàng sốII
trong hình 14.
Hình 14 (Đường số II chạy
từ trên xuống, ý nói cái gốc của nhóm AA là ở
TQ, nhưng vì sao nó không chạy từ dưới lên
trên, nghĩa là nhóm AA mang H.p. từ Đông
nam Á lên TQ?) Tóm lại, theo mấy nhà nói trên, ta
vẫn chưa chắc cái gốc của đám O2a1-M95 ở
đâu. Có lẽ ta phải hỏi “nhà ta”, tức là bà xã của
ta, thì mới chắc. Nhưng chuyện này là chuyện lớn,
mấy bả không quyết định được; vậy
ta phải tự mình suy nghĩ và quyếtđịnh. Ta biết O2a1-M95 tách ra từ
O2-P31, còn O2-P31 thì tách ra từ O-M175 (hình 9). Nhưvậy, nếu
biết hai đám O2-P31* và O-M175* đang ở đâu, ta có
thêm dấu vết để dò ra gốc gác của
O2a1-M95. Biểu 13. Phần trăm đực
rựa thuộc O* và O2* trong 22 nhóm nói những thứ tiếng
Hmong-Mien ởmiền nam TQ, vẽ lại theo Xiaoyun Cai et
al [op. cit.].
Biểu 14. Phần trăm đực
rựa thuộc O* và O2* trong 24 nhóm nói những thứ tiếng
Mon-Khmer ở Đông nam Á, vẽ lại theo Xiaoyun Cai et al
[op. cit.].
Biểu 15: phần trăm đực
rựa thuộc O* và O2* trong 27 nhóm ở Đông Á, vẽ lại
theo Yali Xue et al [op. cit.].
Biểu 16. Phần trăm đực
rựa thuộc O* và O2* trong 24 nhóm ở đông bắc Ấn
Độ, vẽ lại theo Gyaneshwer Chaubey et al [op. cit.].
Biểu 17: phần trăm đực
rựa thuộc O* và O2* trong 7 nhóm Đông nam Á, vẽ lại
theo Tatiana Karafet et al [op. cit.] và Jun-Dong He et al [op. cit.].
Biểu 18:
phần trăm đực rựa thuộc O* và O2* trong 12
nhóm Đông Á, vẽ lại theo Soon-Hee Kim et al [19].
Số liệu biểu 13-18 cho thấy
đại khái như sau:
Nếu O2a1-M95 ra đời ở
đông bắc Ấn Độ, thì ngay đó hoặc gần
đó bây giờ hẳn phải còn O2* hoặc O*, không nhiều
thì ít; đằng này không thấy O2* cũng chẳng thấy
O* ở đó, như vậy có lẽ O2a1-M95 không phải
ra đời ở đông bắc Ấn Độ. Đằng khác, số liệu cho thấy
cả O2* và O* bây giờ còn khá đông ở Lào, như vậy
có lẽ O2a1-M95 đã ra đời trong đám O2 ở
Lào. Còn đám O2* ở Đông bắc
Á thì sao? Hình 9 cho thấy dưới O2 còn một nhánh khác
là O2b1a-47z, mà O2b1a-47z trong sắc dân Nhật Bản chiếm
gần 24% theo Soon-Hee Kim et al [op. cit.], và 22% theo Michael F.
Hammer et al [20]. Đám O2b1a-47z cũng chiếm gần 9%
trong sắc dân Đại Hàn, theo Soon-Hee Kim et al [op. cit.]. Nhưvậy, có lẽ O2b1a-47z đã
ra đời trong đám O2 ở Đông bắc Á. Và ta có thể phác một bức tranh
như sau (hình 15):
Hình 15
Hình 16 Dựa theo Xiaoyun Cai et al [op. cit.], O2a1-M95 ra đời
chừng 20 ngàn năm trước, thì chuyện họ
đi bộ từ Lào qua Indonesia là điều dễ hiểu,
vì từ lúc
đó tới 10 ngàn năm sau, vùng biển giữa bán đảo
Đông Dương với Indonesia vẫn cạn (chỗ
màu xanh dương lợt ở hình 16) chớ chưa ngập
nước như ngày nay. Cũng vậy, biển Hoàng Hải
(Yellow Sea) và eo biển Đại Hàn (Korean Strait) lúc đó
vẫn cạn (chỗ màu xanh dương lợt ở
hình 15) nên đám O2b1a-47z có thể đi bộ từ TQ qua
Nhật Bản và Đại Hàn. Roger Blench [21] dựa theo tài liệu
khảo cổ cũng cho rằng đám AA từ VN xuống
Indonesia (hình 17) trước cả đám nói tiếng
Austronesian, là thứ tiếng mà dân Indonesia đang nói.
Hình 17 Tóm lại, O2a1-M95* là đám đực rựa “thổ
địa” ở Đông nam Á, sinh ra ở một nơi
nào đó giữa Lào và Thái ngày nay, gần như hết thảy
những sắc dân ở Đông nam Á ngày nay, chừng 4 gã
thì có 1 gã thuộc về O2a1-M95*, chưa kể những sắc
dân ở nam TQ và đông bắc Ấn Độ. Nói nôm na, theo số liệu đã nêu trên, chừng 10%
đàn ông VN là anh em với hơn 20% đàn ông người
Mường, người Chàm ở VN, người Lamet ở
Lào, người Zhuang ở nam TQ, người Ho ở
đông bắc Ấn Độ, thí dụ như vậy. O2a1-M95 với tuổi đời hơn 20 ngàn năm hẳn
đã ở VN sớm hơn so với nhiều đám khác;
nhưng vì sao bây giờ họ lại thưa hơn những
đám khác thì mai mốt ta sẽ có dịp tìm hiểu kỹ
hơn. O2a1-M95* bên TQ hẳn cũng góp sức lập nên những
xứ xưa như Việt, Sở, và là cái “lõi” của những
nhóm người xưa như Bách Bộc, Bách Việt nêu ở
phần 2. Jerry Norman [22] nêu lên nhiều thí dụ
cho thấy tiếng TQ có mượn tiếng AA, và đó
là chứng cớ cho thấy những đám nói tiếng
AA [ta hiểu đó là những đám O2a1-M95*] đã có mặt
ở nam TQ từ 2500 tới 3000 năm trước. NOTES: [1] Major East-West Division Underlies
Y Chromosome Stratification Across Indonesia [2] Patrilineal Perspective on the
Austronesian Diffusion in Mainland Southeast Asia [3] International Society of Genetic Genealogy (2012). Y-DNA Haplogroup Tree 2013, Version: 8.11, Date: 14-Jan-2013,
http://www.isogg.org/tree/ 28-Jan-2013. [5] Y chromosome haplotypes reveal
prehistorical migrations to the Himalayas [6] The distribution of Y chromosome haplogroups in the nationalities from
Yunnan Province of China [7]Male demography in East Asia: a north-south contrast in human
population expansion times [8] Origin of
Hakka and Hakkanese: A Genetics Analysis [10] Y-chromosome evidence suggests a common paternal heritage of
Austro-Asiatic populations [12] The Peopling of Korea Revealed by Analyses of Mitochondrial DNA and
Y-Chromosomal Markers [13]Proto-East Asian and the Origin and
Dispersal of the Languages of East and Southeast Asia and the Pacific [14] Rice and the Austroasiatic and
Hmong-Mien homelands [15] Some thoughts
on the problem of the Austro-Asiatic homeland [16] The Austroasiatic Urheimat: the
Southeastern Riverine Hypothesis [17] Family
Diversity and the Austroasiatic Homeland [20]Dual origins
of the Japanese: common ground for hunter-gatherer and farmer Y
chromosomes [21] Was there
an Austroasiatic presence in island Southeast Asia prior to the Austronesian
expansion? [22] The Austroasiatics in Ancient South China: Some Lexical Evidence 28-Jan-2013 Đ. N. Giao |
























|
|